

Vision models are pivotal in enabling machines to interpret and analyze visual data. They are integral to tasks such as image classification, object detection, and segmentation, where raw pixel values from images are transformed into meaningful features through trainable layers. These systems, including convolutional neural networks (CNNs) and vision transformers, rely on efficient training processes to optimize performance. A critical focus is on the first layer, where embeddings or pre-activations are generated, forming the foundation for subsequent layers to extract higher-level patterns.
A major issue in the training of vision models is the disproportionate influence of image properties like brightness and contrast on the weight updates of the first layer. Images with extreme brightness or high contrast create larger gradients, leading to significant weight changes, while low-contrast images contribute minimally. This imbalance introduces inefficiencies, as certain input types dominate the training process. Resolving this discrepancy is crucial to ensure all input data contributes equally to the model’s learning, thereby improving convergence and overall performance.
Traditional approaches to mitigate these challenges focus on preprocessing techniques or architectural modifications. Methods like batch normalization, weight normalization, and patch-wise normalization aim to standardize data distributions or enhance input consistency. While effective in improving training dynamics, these strategies must address the root issue of uneven gradient influence in the first layer. Moreover, they often require modifications to the model architecture, increasing complexity and reducing compatibility with existing frameworks.
Researchers from Stanford University and the University of Salzburg proposed TrAct (Training Activations), a novel method for optimizing the first-layer training dynamics in vision models. Unlike traditional methods, TrAct retains the original model architecture and modifies the optimization process. By drawing inspiration from embedding layers in language models, TrAct ensures that gradient updates are consistent and unaffected by input variability. This approach bridges the gap between how language and vision models handle initial layers, significantly improving training efficiency.
The TrAct methodology involves a two-step process. First, it performs a gradient descent step on the first-layer activations, generating an activation proposal. Second, it updates the first-layer weights to minimize the squared distance to this proposal. This closed-form solution requires efficient computation involving the inversion of a small matrix related to the input dimensions. The method introduces a hyperparameter, λ, which controls the balance between input dependence and gradient magnitude. The default value for λ works reliably across various models and datasets, making the method straightforward to implement. Furthermore, TrAct is minimally invasive, requiring modifications only in the gradient computation of the first layer, ensuring compatibility with existing training pipelines.
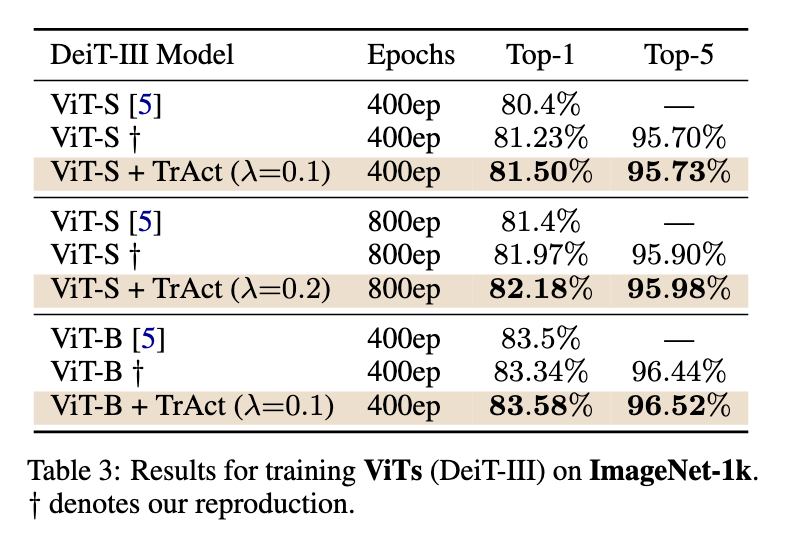
Experimental results showcase the significant advantages of TrAct. In CIFAR-10 experiments using ResNet-18, TrAct achieved test accuracies comparable to baseline models but required substantially fewer epochs. For instance, with the Adam optimizer, TrAct matched baseline accuracy after 100 epochs, whereas the baseline required 400. Similarly, on CIFAR-100, TrAct improved top-1 and top-5 accuracies for 33 out of 36 tested model architectures, with an average accuracy improvement of 0.49% for top-1 and 0.23% for top-5 metrics. On ImageNet, training ResNet-50 for 60 epochs with TrAct yielded accuracies nearly identical to baseline models trained for 90 epochs, demonstrating a 1.5× speedup. TrAct’s efficiency was evident in larger models, such as vision transformers, where runtime overheads were minimal, ranging from 0.08% to 0.25%.
TrAct’s impact extends beyond accelerated training. The method improves accuracy without architectural changes, ensuring existing systems integrate the approach seamlessly. Furthermore, it is robust across diverse datasets and training setups, maintaining high performance irrespective of input variability or model type. These results emphasize the potential of TrAct to redefine first-layer training dynamics in vision models.
TrAct offers a groundbreaking solution to a longstanding problem in vision models by addressing the disproportionate influence of input properties on training. The method’s simplicity, effectiveness, and compatibility with existing systems make it a promising tool for advancing the efficiency & accuracy of machine learning models in visual tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link














{kind=link}