

High-resolution, photorealistic image generation presents a multifaceted challenge in text-to-image synthesis, requiring models to achieve intricate scene creation, prompt adherence, and realistic detailing. Among current visual generation methodologies, scalability remains an issue for lowering computational costs and achieving accurate detail reconstructions, especially for the VAR models, which suffer further from quantization errors and suboptimal processing techniques. Such opportunities should be addressed to open up new frontiers in the applicability of generative AI, from virtual reality to industrial design to digital content creation.
Existing methods primarily leverage diffusion models and traditional VAR frameworks. Diffusion models utilize iterative denoising steps, which result in high-quality images but at the cost of high computational requirements, limiting their usability for applications requiring real-time processing. VAR models attempt to produce better images by processing discrete tokens; however, their dependency on index-wise token prediction exacerbates cumulative errors and reduces fidelity in detail. Such models also suffer from large latency and inefficiency because of their raster-scan generation methodology. This need shows that novel approaches must be created focused on improving scalability, efficiency, and the representation of visual detail.
Researchers from ByteDance propose Infinity, a groundbreaking framework for text-to-image synthesis, redefining the traditional approach to overcome key limitations in high-resolution image generation. Replacing index-wise tokenization with bitwise tokens resulted in a finer grain of representation, leading to the reduction of quantization errors and allowing for greater fidelity in the output. The framework incorporates an Infinite-Vocabulary Classifier (IVC) to scale the tokenizer vocabulary to 2^64, a significant leap that minimizes memory and computational demands. Furthermore, the incorporation of Bitwise Self-Correction (BSC) tackles aggregate errors that arise during training by emulating prediction inaccuracies and re-quantizing features to improve model resilience. These developments facilitate effective scalability and set new benchmarks for high-resolution, photorealistic image generation.
The Infinity architecture comprises three core components: a bitwise multi-scale quantization tokenizer that converts image features into binary tokens to reduce computational overhead, a transformer-based autoregressive model that predicts residuals conditioned on text prompts and prior outputs, and a self-correction mechanism that introduces random bit-flipping during training to enhance robustness against errors. Extensive sets like LAION and OpenImages are used for the training process with incremental resolution increases from 256×256 to 1024×1024. With refined hyperparameters and advanced techniques of scaling, the framework achieves excellent performances in terms of scalability along with detailed reconstruction.

Infinity presents impressive advancement in text-to-image synthesis, showing superior results on key evaluation metrics. The system outperforms current models, including SD3-Medium and PixArt-Sigma, with a GenEval score of 0.73 and reducing the Fréchet Inception Distance (FID) to 3.48. The system shows impressive efficiency, producing 1024×1024 images within 0.8 seconds, which is highly indicative of substantial improvements in both speed and quality. It consistently produced outputs that were visually authentic, rich in detail, and responsive to prompts, which was confirmed by higher human preference ratings and a proven capacity to adhere to intricate textual directives in several contexts.

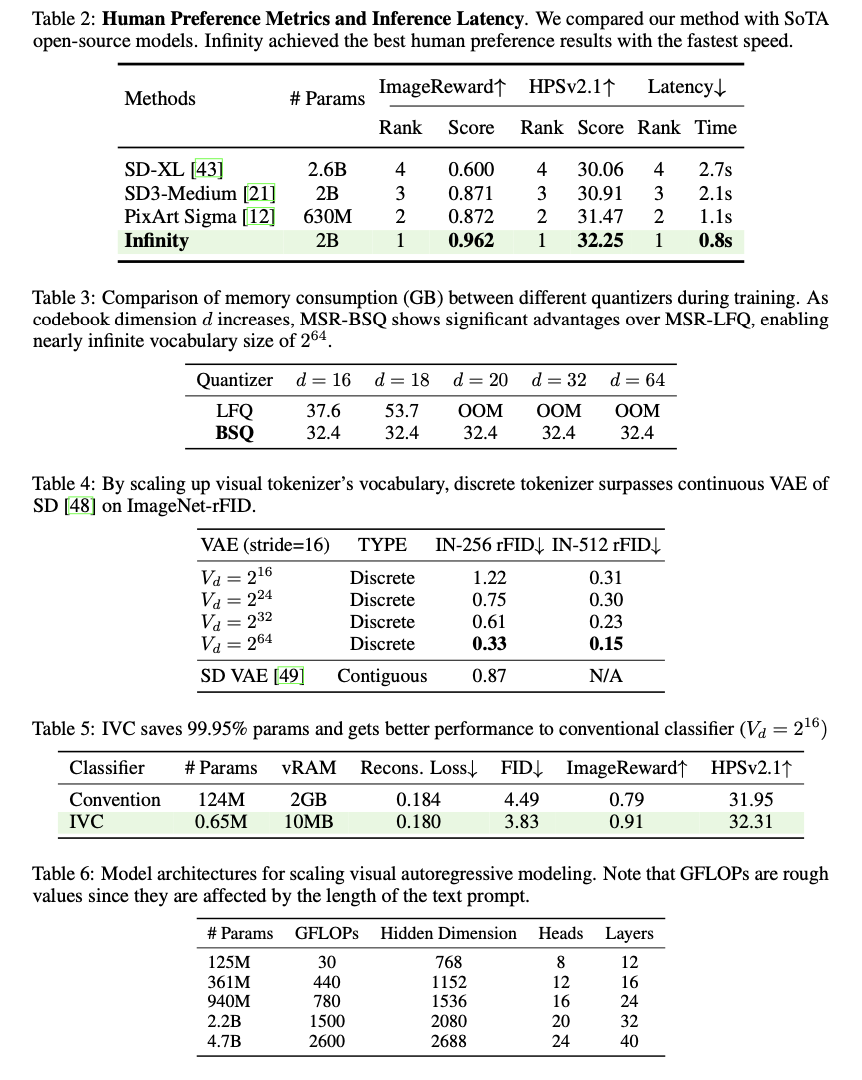
In conclusion, Infinity establishes a new benchmark in the field of high-resolution text-to-image synthesis through its innovative design to effectively overcome long-standing scalability and fidelity-of-detail challenges. With strong self-correction combined with bitwise tokenization and large vocabulary augmentation, it supports efficient and high-quality generative modeling. This work has redefined the limits of autoregressive synthesis and opens avenues for significant progress in generative AI, which inspires further research in this area.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
Credit: Source link


 Protocol")











{kind=link}