

Latent diffusion models are advanced techniques for generating high-resolution images by compressing visual data into a latent space using visual tokenizers. These tokenizers reduce computational demands while retaining essential details. However, such models suffer from a critical challenge: increasing the dimensions of the token feature increases reconstruction quality but decreases image generation quality. It thus creates an optimization dilemma in which achieving a detailed reconstruction compromises the ability to generate visually appealing images.
Existing methods need much more computational power, which creates limitations. This presents difficulties in achieving both detailed reconstruction and high-quality image generation efficiently. Visual tokenizers like VAEs, VQVAE, and VQGAN compress visual data but struggle with poor codebook utilization and inefficient optimization in larger latent spaces. Continuous VAE diffusion models improve reconstruction but harm generation performance, increasing costs—methods like MAGVIT-v2 and REPA attempt to address these issues but add complexity without resolving core trade-offs. Diffusion Transformers, widely used for scalability, also face slow training speeds despite enhancements like SiT or MaskDiT. These tokenizers and latent spaces inefficiencies remain a key barrier to effectively integrating generative and reconstruction tasks.
To address optimization challenges in latent diffusion models, researchers from Huazhong University of Science and Technology proposed the VA-VAE method, which integrates a Vision Foundation model alignment loss (VF Loss) to enhance the training of high-dimensional visual tokenizers. This framework regularizes the latent space with element and pair-wise similarities, making it more aligned with the Vision Foundation model. VF Loss includes marginal cosine similarity loss and marginal distance matrix similarity loss, further improving alignment without limiting the latent space’s capacity. As a result, the framework enhances reconstruction and generation performance by addressing the intensity concentration in latent space distributions.
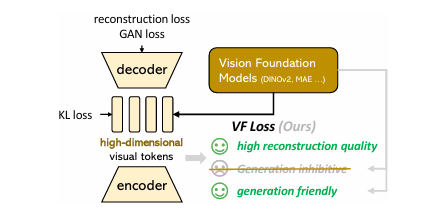
Researchers integrated VF loss within the latent diffusion system to improve reconstruction and generation performance by using LightningDiT, optimizing convergence and scalability. The VF loss, particularly with foundation models like DINOv2, accelerated convergence, with a speedup of up to 2.7x in training time. Experiments with different configurations, such as tokenizers with and without VF loss, showed that VF loss notably improved performance, especially in high-dimensional tokenizers, and bridged the gap between generative performance and reconstruction. The loss of VF also improved scalability, optimizing models ranging from 0.1B to 1.6B parameters so that high-dimensional tokenizers kept strong scalability without significant performance loss. The results showed the method’s effectiveness in improving generative performance and convergence speed and minimizing cfg dependency.
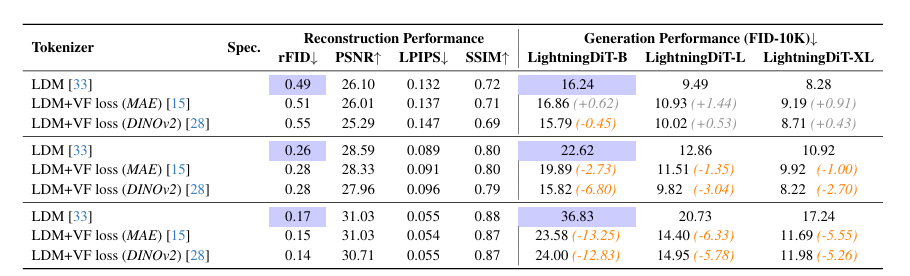

In conclusion, the proposed framework VA-VAE and LightningDiT address the optimization challenges in latent diffusion systems. VA-VAE aligns the latent space with vision models, improving convergence and uniformity, while LightningDiT accelerates training. The approach achieves FID on ImageNet with a 21.8× speedup. This work offers a foundation for future research, enabling further optimization and scalability improvements in generative models with reduced training costs.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Credit: Source link
 Platform to Advance Physical AI Development")



































{kind=link}