
{kind=link}
Autoregressive (AR) models have changed the field of image generation, setting new benchmarks in producing high-quality visuals. These models break down the image creation process into sequential steps, each token generated based on prior tokens, creating outputs with exceptional realism and coherence. Researchers have widely adopted AR techniques for computer vision, gaming, and digital content creation applications. However, the potential of AR models is often constrained by their inherent inefficiencies, particularly their slow generation process, which remains a significant hurdle in real-time applications.
Among many concerns, a critical one that AR models face is their speed. The token-by-token generation process is inherently sequential, meaning each new token must wait for its predecessor to complete. This approach limits scalability and results in high latency during image generation tasks. For instance, generating a 256×256 image using traditional AR models like LlamaGen requires 256 steps, translating to approximately five seconds on modern GPUs. Such delays hinder their deployment in applications that demand instantaneous results. Also, while AR models excel in maintaining the fidelity of their outputs, they struggle to meet the growing demand for both speed and quality in large-scale implementations.
Efforts to accelerate AR models have yielded various methods, such as predicting multiple tokens simultaneously or adopting masking strategies during generation. These approaches aim to reduce the required steps but often compromise the quality of the generated images. For example, in multi-token generation techniques, the assumption of conditional independence among tokens introduces artifacts, undermining the cohesiveness of the output. Similarly, masking-based methods allow for faster generation by training models to predict specific tokens based on others, but their effectiveness diminishes when generation steps are drastically reduced. These limitations highlight the need for a new approach to enhance AR model efficiency.
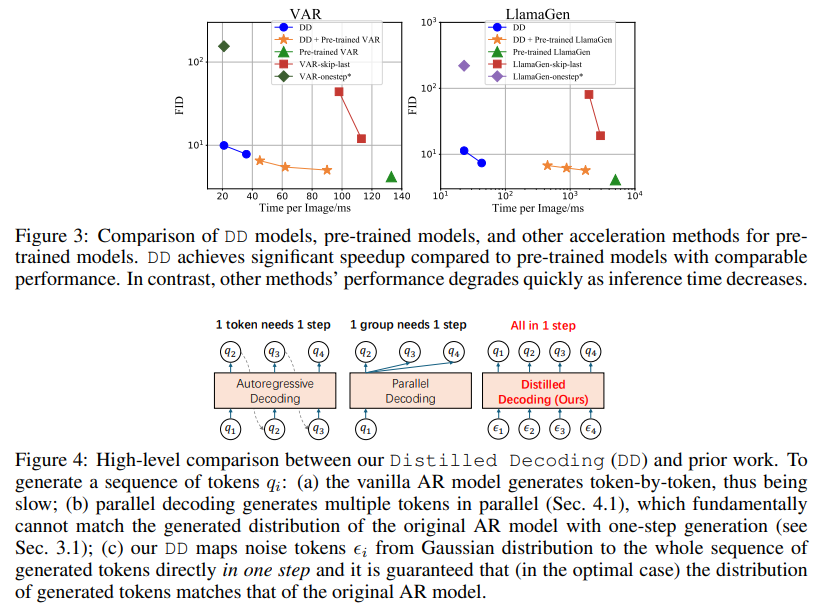
Tsinghua University and Microsoft Research researchers have introduced a solution to these challenges: Distilled Decoding (DD). This method builds on flow matching, a deterministic mapping that connects Gaussian noise to the output distribution of pre-trained AR models. Unlike conventional methods, DD does not require access to the original training data of the AR models, making it more practical for deployment. The research demonstrated that DD can transform the generation process from hundreds of steps to as few as one or two while preserving the quality of the output. For example, on ImageNet-256, DD achieved a speed-up of 6.3x for VAR models and an impressive 217.8x for LlamaGen, reducing generation steps from 256 to just one.
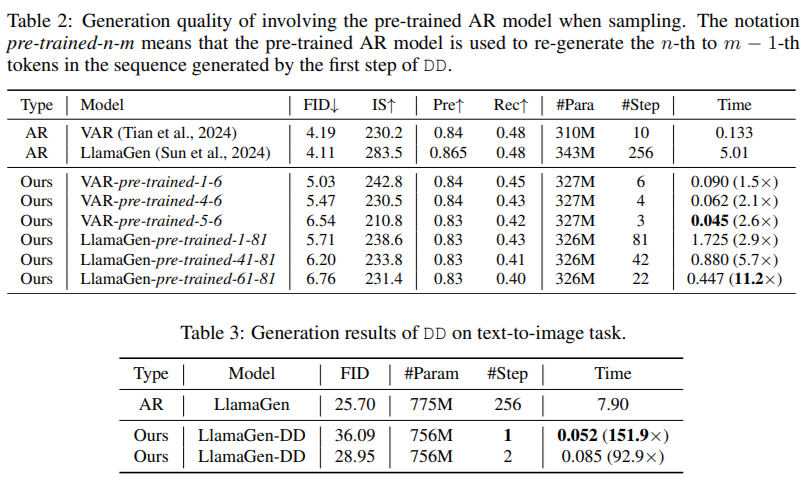
The technical foundation of DD is based on its ability to create a deterministic trajectory for token generation. Using flow matching, DD maps noisy inputs to tokens to align their distribution with the pre-trained AR model. During training, the mapping is distilled into a lightweight network that can directly predict the final data sequence from a noise input. This process ensures faster generation and provides flexibility in balancing speed and quality by allowing intermediate steps when needed. Unlike existing methods, DD eliminates the trade-off between speed and fidelity, enabling scalable implementations across diverse tasks.
In experiments, DD highlights its superiority over traditional methods. For instance, using VAR-d16 models, DD achieved one-step generation with an FID score increase from 4.19 to 9.96, showcasing minimal quality degradation despite a 6.3x speed-up. For LlamaGen models, the reduction in steps from 256 to one resulted in an FID score of 11.35, compared to 4.11 in the original model, with a remarkable 217.8x speed improvement. DD demonstrated similar efficiency in text-to-image tasks, reducing generation steps from 256 to two while maintaining a comparable FID score of 28.95 against 25.70. The results underline DD’s ability to drastically enhance speed without significant loss in image quality, a feat unmatched by baseline methods.
Several key takeaways from the research on DD include:
- DD reduces generation steps by orders of magnitude, achieving up to 217.8x faster generation than traditional AR models.
- Despite the accelerated process, DD maintains acceptable quality levels, with FID score increases remaining within manageable ranges.
- DD demonstrated consistent performance across different AR models, including VAR and LlamaGen, regardless of their token sequence definitions or model sizes.
- The approach allows users to balance quality and speed by choosing one-step, two-step, or multi-step generation paths based on their requirements.
- The method eliminates the need for the original AR model training data, making it feasible for practical applications in scenarios where such data is unavailable.
- Due to its efficient distillation approach, DD can potentially impact other domains, such as text-to-image synthesis, language modeling, and image generation.
In conclusion, with the introduction of Distilled Decoding, researchers have successfully addressed the longstanding speed-quality trade-off that has plagued AR generation processes by leveraging flow matching and deterministic mappings. The method accelerates image synthesis by reducing steps drastically and preserves the outputs’ fidelity and scalability. With its robust performance, adaptability, and practical deployment advantages, Distilled Decoding opens new frontiers in real-time applications of AR models. It sets the stage for further innovation in generative modeling.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link