
{kind=link}
Autoregressive models are used to generate sequences of discrete tokens. The next token is conditioned by the preceding tokens in a given sequence in the approach. Recent research showed that generating sequences of continuous embeddings autoregressively is also feasible. However, such Continuous Autoregressive Models (CAMs) generate these embeddings similarly sequentially, but they face challenges such as a decline in generation quality over extended sequences. This decline occurs because of error accumulation during the inference process, where small prediction errors compound as the sequence length increases, resulting in degraded output.
Traditional models for autoregressive image and audio generation relied on discretizing data into tokens using VQ-VAEs to enable models to work within a discrete probability space. Such an approach introduces significant drawbacks, including additional losses when training VAEs and added complexity. Although continuous embeddings are more efficient, they tend to accumulate errors during inference, causing distribution shifts and lowering the generated output’s quality. Recent attempts to bypass quantization by training on continuous embeddings have failed to produce convincing results due to cumbersome non-sequential masking and fine-tuning techniques impair efficiency and restrict further usage within the research community.
To solve this, a group of researchers from Queen Mary University and Sony Computer Science Laboratories conducted detailed research and proposed a method to counteract error accumulation and train purely autoregressive models on ordered sequences of continuous embeddings without adding complexity. To overcome the drawbacks of standard AMs, CAM introduced a noise augmentation strategy during training to simulate the errors that occur during inference. This method combined the strengths of Rectified Flow (RF) and AMs for continuous embeddings.
The main concept behind the CAM proposed was injecting noise in the sequence during training to simulate error-prone inference conditions. It then applied iterative reverse diffusion to generate sequences autoregressively, progressively improving predictions while correcting mistakes. CAM was pre-trained to be robust for error accumulation during the generation of longer sequences through training with noisy sequences. This process improved the general quality of the generated sequences, especially for tasks such as music generation, for which the quality of each predicted element proved crucial to the overall output.
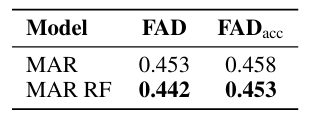
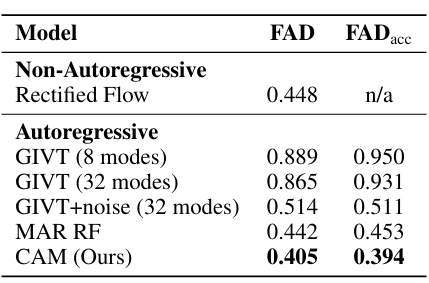
The method was tested on a music dataset and compared with the experiment’s autoregressive and non-autoregressive baselines. The researchers used a dataset of about 20,000 single-instrument recordings with 48 kHz stereo audio for training and evaluation. They processed the data with Music2Latent to create continuous latent embeddings with a 12 Hz sampling rate. Based on a transformer with 16 layers and 150 million parameters, CAM was trained using AdamW for 400k iterations. CAM performed better than the other models, with FAD of 0.405 and FADacc of 0.394, compared to baselines like GIVT or MAR. CAM provided better quality basics for reconstructing the sound spectrum and avoiding the error buildup in long sequences; the noise augmentation approach also helped to enhance the GIVT scores.
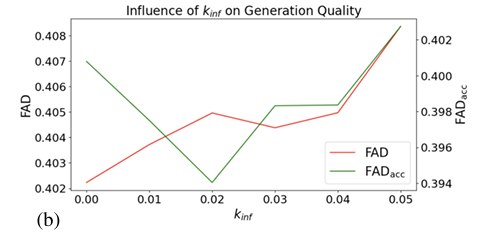
In summary, the proposed method trains purely autoregressive models on continuous embeddings that directly address the error accumulation problem. A noise injection technique calibrated carefully at inference time further reduces error accumulation. This method opens the path for real-time and interactive audio applications that benefit from the efficiency and sequential nature of autoregressive models and can be used as a baseline for further research in the domain!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Credit: Source link