
")
Large Language Models (LLMs) have demonstrated remarkable similarities to human cognitive processes’ ability to form abstractions and adapt to new situations. Just as humans have historically made sense of complex experiences through fundamental concepts like physics and mathematics, autoregressive transformers now show comparable capabilities through in-context learning (ICL). Recent research has highlighted how these models can adapt to tricky tasks without parameter updates, suggesting the formation of internal abstractions similar to human mental models. Studies have begun exploring the mechanistic aspects of how pretrained LLMs represent latent concepts as vectors in their representations. However, questions remain about the underlying reasons for these task vectors’ existence and their varying effectiveness across different tasks.
Researchers have proposed several theoretical frameworks to understand the mechanisms behind in-context learning in LLMs. One significant approach views ICL through a Bayesian framework, suggesting a two-stage algorithm that estimates posterior probability and likelihood. Parallel to this, studies have identified task-specific vectors in LLMs that can trigger desired ICL behaviors. At the same time, other research has revealed how these models encode concepts like truthfulness, time, and space as linearly separable representations. Through mechanistic interpretability techniques such as causal mediation analysis and activation patching, researchers have begun to uncover how these concepts emerge in LLM representations and influence downstream ICL task performance, demonstrating that transformers implement different algorithms based on inferred concepts.
Researchers from the Massachusetts Institute of Technology and Improbable AI introduce the concept encoding-decoding mechanism, providing a compelling explanation for how transformers develop internal abstractions. Research on a small transformer trained on sparse linear regression tasks reveals that concept encoding emerges as the model learns to map different latent concepts into distinct, separable representation spaces. This process operates in tandem with the development of concept-specific ICL algorithms through concept decoding. Testing across various pretrained model families, including Llama-3.1 and Gemma-2 in different sizes, demonstrates that larger language models exhibit this concept encoding-decoding behavior when processing natural ICL tasks. The research introduces Concept Decodability as a geometric measure of internal abstraction formation, showing that earlier layers encode latent concepts while latter layers condition algorithms on these inferred concepts, with both processes developing interdependently.
The theoretical framework for understanding in-context learning draws heavily from a Bayesian perspective, which proposes that transformers implicitly infer latent variables from demonstrations before generating answers. This process operates in two distinct stages: latent concept inference and selective algorithm application. Experimental evidence from synthetic tasks, particularly using sparse linear regression, demonstrates how this mechanism emerges during model training. When trained on multiple tasks with different underlying bases, models develop distinct representational spaces for different concepts while simultaneously learning to apply concept-specific algorithms. The research reveals that concepts sharing overlaps or correlations tend to share representational subspaces, suggesting potential limitations in how models distinguish between related tasks in natural language processing.
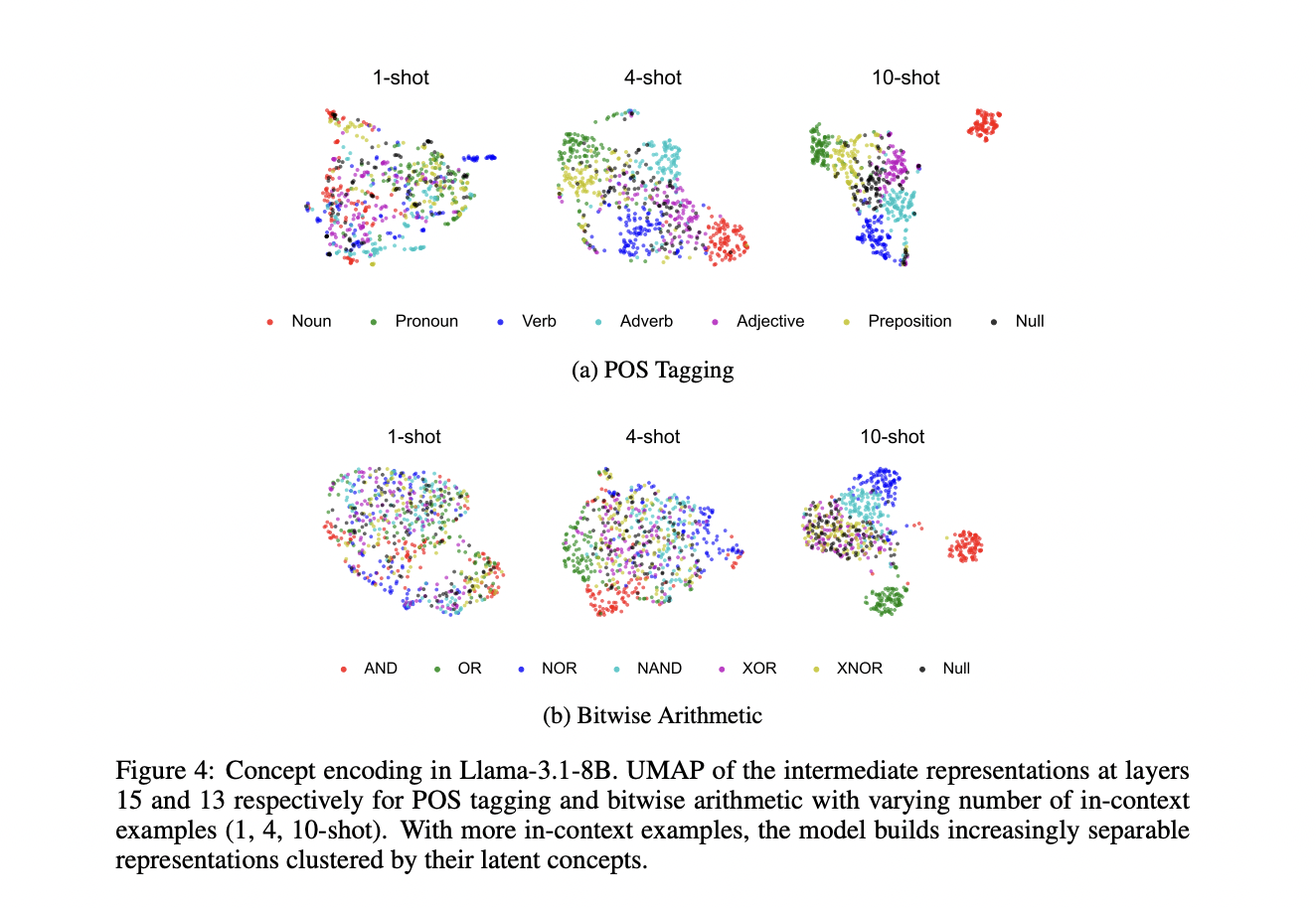
The research provides compelling empirical validation of the concept encoding-decoding mechanism in pretrained Large Language Models across different families and scales, including Llama-3.1 and Gemma-2. Through experiments with part-of-speech tagging and bitwise arithmetic tasks, researchers demonstrated that models develop more distinct representational spaces for different concepts as the number of in-context examples increases. The study introduces Concept Decodability (CD) as a metric to quantify how well latent concepts can be inferred from representations, showing that higher CD scores correlate strongly with better task performance. Notably, concepts frequently encountered during pretraining, such as nouns and basic arithmetic operations, show clearer separation in representational space compared to more complex concepts. The research further demonstrates through finetuning experiments that early layers play a crucial role in concept encoding, with modifications to these layers yielding significantly better performance improvements than changes to later layers.

The concept encoding-decoding mechanism provides valuable insights into several key questions about Large Language Models’ behavior and capabilities. The research addresses the varying success rates of LLMs across different in-context learning tasks, suggesting that performance bottlenecks can occur at both the concept inference and algorithm decoding stages. Models show stronger performance with concepts frequently encountered during pretraining, such as basic logical operators, but may struggle even with known algorithms if concept distinction remains unclear. The mechanism also explains why explicit modeling of latent variables doesn’t necessarily outperform implicit learning in transformers, as standard transformers naturally develop effective concept encoding capabilities. Also, this framework offers a theoretical foundation for understanding activation-based interventions in LLMs, suggesting that such methods work by directly influencing the encoded representations that guide the model’s generation process.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link














{kind=link}